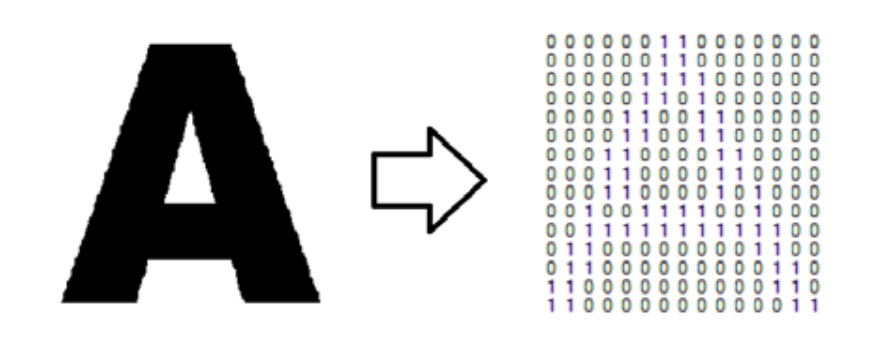
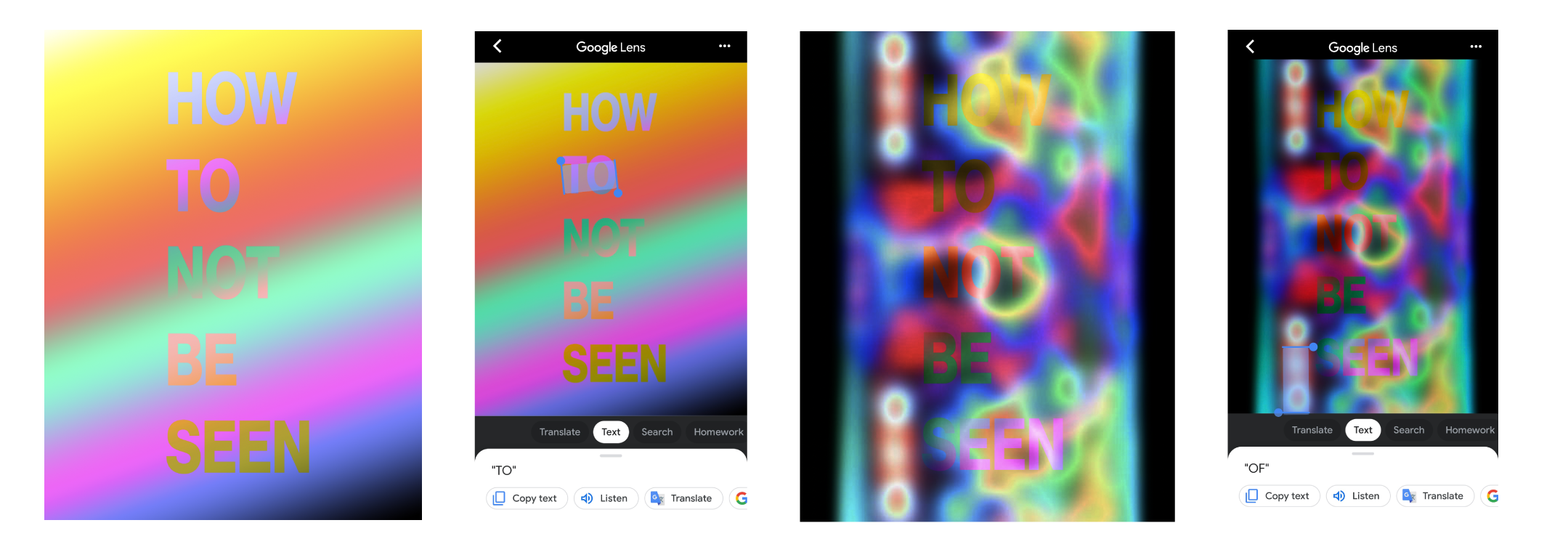
Optical character recognition, or OCR, are technologies to convert images of text into digitized text data. OCR programs extract text from scanned documents, scene photos, screenshots and image-only pdfs so that the text data can be archived, edited, searched and translated.
OCR technologies are quite beneficial to us. Resources like old printed books, newspapers and historical records are being digitized into PDFs. We can choose to take notes with our hands and ink, and have OCR convert our handwritings into digitized text. We can translate foreign text on product ingredient labels just by pointing our cell phone cameras at them.